
[2021-02-12] 새로운 압출기
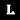 폭스
00:09:33
100
클리어 28명
참여 46명
폭스
00:09:33
100
클리어 28명
참여 46명
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
한 개발자가 새로운 압출기를 만든 후 실험을 하기 위해 어떤 산으로 향했다.
이 압출기는 어떠한 물체든지 원하는 부분만 추출하여 얻어낼 수 있다.
압출기의 사용법과 사용한 예시가 다음과 같을 때 이 산의 이름을 유추하시오.
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
by  체난
체난
브로켄
우선 압출기의 원리를 파악한 후 ?에 들어갈 것이 무엇인지 부터 생각해야 합니다.
예시와 문제의 그림에서 투입하는 물체의 이름을 한글로 표현하면 전부 숫자가 들어가는 것을 알 수 있습니다.
물체의 이름을 한글로 표현한 후 철자를 나누고 숫자를 n이라 하면 n번째에 있는 철자가 추출되는 방식입니다.
예시에 있는 네'이'버와 '구'글, 카카'오'톡을 보면 네이버는 2번째의 철자인 ㅔ가 남고 나머지 5개의 철자들은 찌꺼기로 걸러집니다.
구글의 경우 9번째의 철자가 없으므로 추출이 되지 못하고 5개의 철자 모두가 걸러집니다. 그리고 카카오톡 또한 5번째의 철자인 ㅇ만 남고 나머지 8개의 철자가 찌꺼기로 걸러집니다.
예시를 통해 이 원리를 파악한 후 문제에 있는 것들을 똑같이 적용시켜보면 '오'뚜기는 5번째의 철자인 ㄱ이 추출되고 트와'이'스는 2번째의 철자인 ㅡ가 추출됩니다. 그 이후로 레'일'등의 ㄹ과 '이'스라엘의 ㅣ, '삼'성의 ㅁ, 자'일'의 ㅈ, 마지막으로 아'이'슬란드의 ㅏ까지 걸러지게 됩니다. 그리고 무지개색깔로 이루어진 것을 보았을 때 이를 무지개처럼 정렬시켜 줄 수 있고 이를 굳히기 위해 위에서 바라보라고 했으므로 위에서 바라보게 되면 다음 그림과 같이 표현될 수 있습니다.
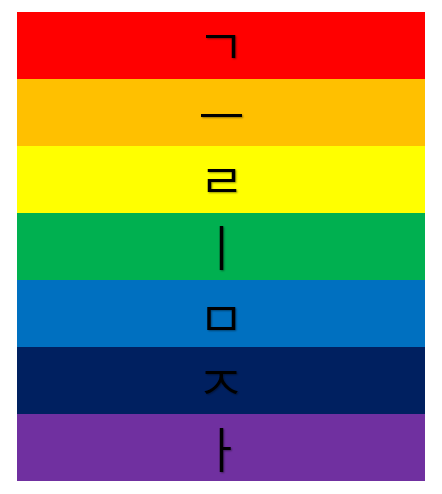
결과적으로 그림자라는 것을 얻을 수 있는데 이는 무지개 안에 그림자가 있는 것을 표현하고 있다는 것을 알 수 있습니다.
실제로 무지개 안에 그림자가 비춰지는 현상을 '브로켄의 요괴'라고 합니다. 이 이름의 유래는 독일의 브로켄이라는 산에서 최초로 목격되었기 때문에 붙여진 이름이며 이 현상을 보고 있는 이 '산'의 명칭을 유추하라고 했으므로 답은 브로켄이 됩니다.